

Scrapy新手上路
- 蒙面西红柿
- 3,406
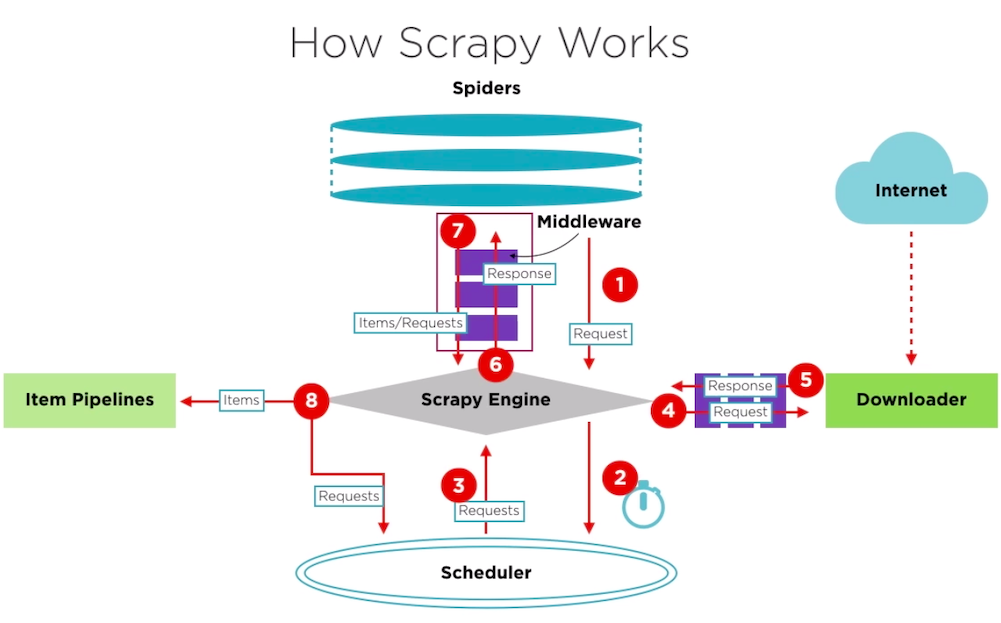
Scrapy 是用 Python 实现的一个为了爬取网站数据、提取结构性数据而编写的应用框架。Scrapy 常应用在包括数据挖掘,信息处理或存储历史数据等一系列的程序中。通常我们可以很简单的通过 Scrapy 框架实现一个爬虫,抓取指定网站的内容或图片。
1. 新建项目
进入项目目录,运行如下命令:
scrapy startproject mySpider其中, mySpider 为项目名称,可以看到将会创建一个 mySpider 文件夹,目录里包含items.py, middlewares.py, piplines.py, setting.py等文件
2. 创建爬虫
在当前目录下输入命令,将在mySpider/spider目录下创建一个名为amzcast的爬虫,并指定爬取域的范围:
scrapy genspider amzcast "amazon.co.uk"本示例将爬取亚马逊商品页面的用户评论
import scrapy
class AmzcastSpider(scrapy.Spider):
name = "amzcast"
allowed_domains = ['amazon.co.uk']
start_urls = (
"亚马逊商品页面URL",
)
def parse(self, response):
pass3. 明确爬取的item
本示例将爬取用户评论,因此item只有review一项。若要同时爬取用户名,时间等,应当在此处添加。
class ReviewItem(scrapy.Item):
# define the fields for your item here like:
review = scrapy.Field()item确定下来以后,返回修改第二部中自动生成的爬虫文件,修改parse方法使其存储用户评论。
def parse(self, response):
reviews = []
command = response.xpath("chrome可以直接导出xpath").extract()
for i in range(0, len(command)):
review = ReviewItem()
command[i] = command[i].replace(u'\xa3', u' ')
review['review'] = command[i]
reviews.append(review)
return reviews4. 运行爬虫
scrapy crawl amzcast -o reviews.csv运行爬虫并将爬取的信息保存为一个csv文件。Scrapy支持保存为json,jsonl,csv和xml文件。
5. 使用Python运行脚本而不是控制台
为了能让用户选择需要爬取什么网页,本项目创建了一个基于Tkinter的用户界面。因此,爬取网页的URL定义与爬虫的运行需要在外部完成而非控制台。效果如下:
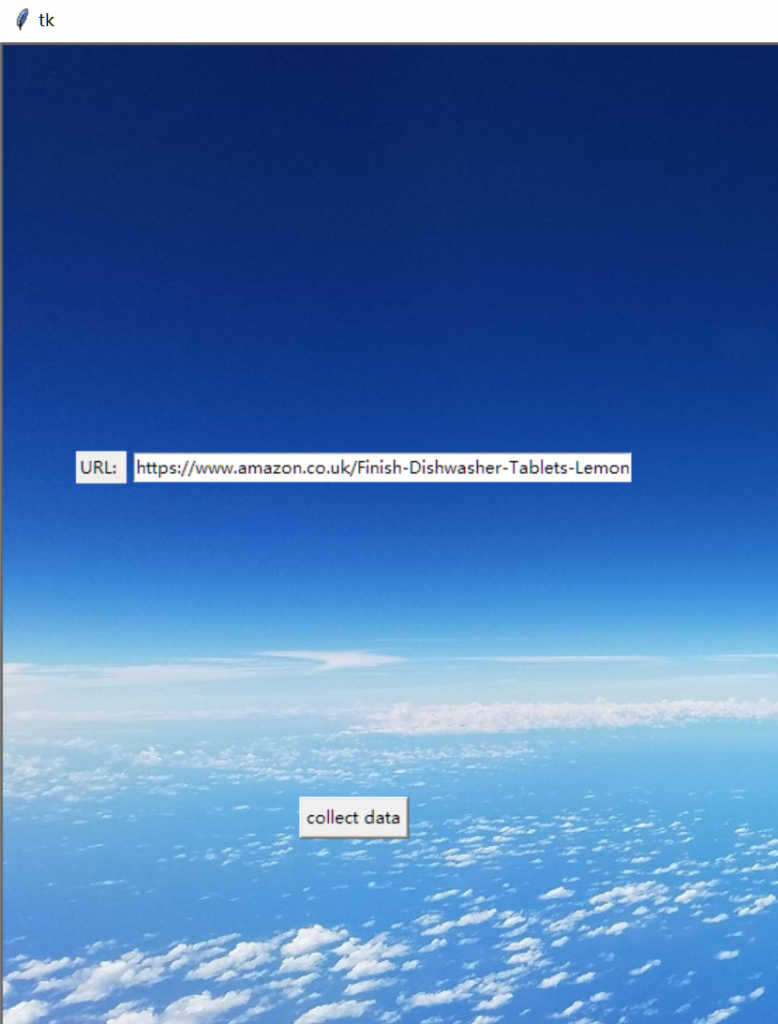
使用如下方法在外部定义爬取网页的URL:
# 用户按下collect data按钮以后获取URL
AmzcastSpider.start_urls.append(urlEntry.get())运行Scrapy进程:
# start scrapy process
process = CrawlerProcess(settings={
"FEEDS": {
"items.json": {"format": "json"},
},
})
process.crawl(AmzcastSpider)
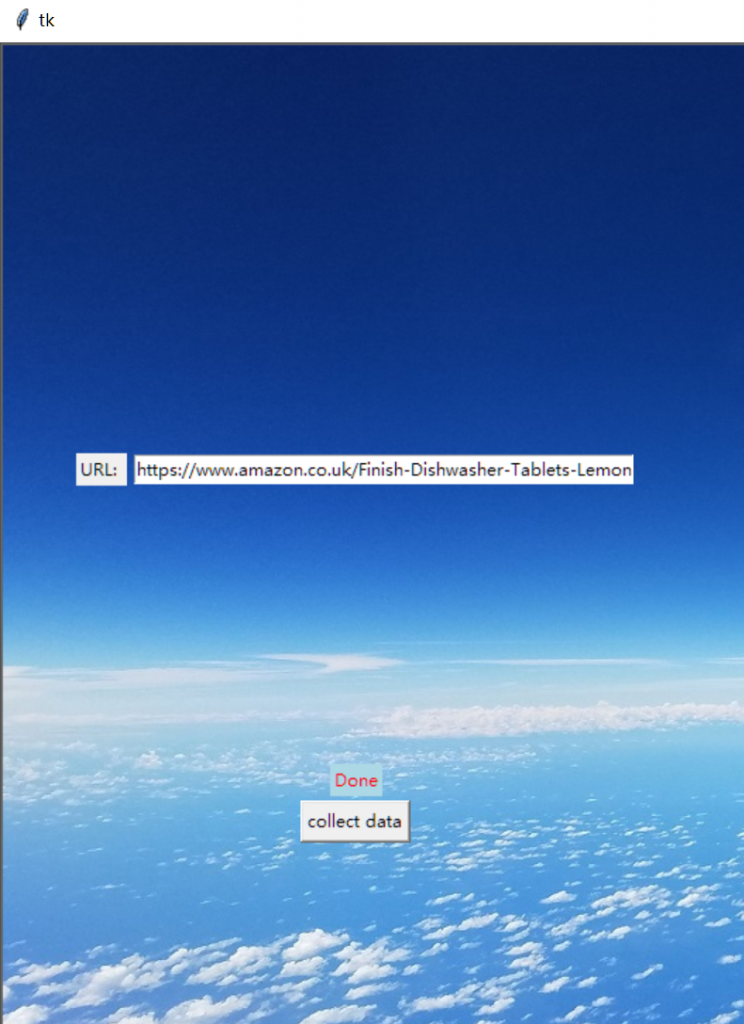
process.start() # the script will block here until the crawling is finished爬取结束以后给用户一个反馈:
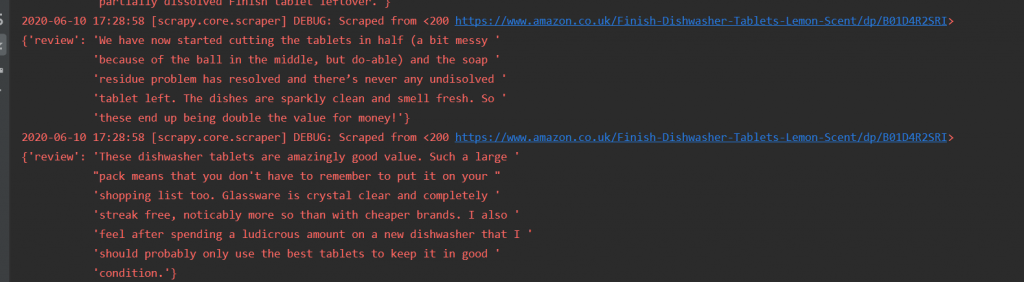
从控制台可以看到评论已经成功爬取了:
但是这么做也有一个缺点,就是不能使用Scrapy自带的导出评论功能。此项目通过在amazcast下import pandas,使用dataframe自带的.to_csv导出
df = pd.DataFrame(reviews)
df.to_csv('./reviews.csv', index=False)保存下来的文件为reveiws.csv,内容如下图:
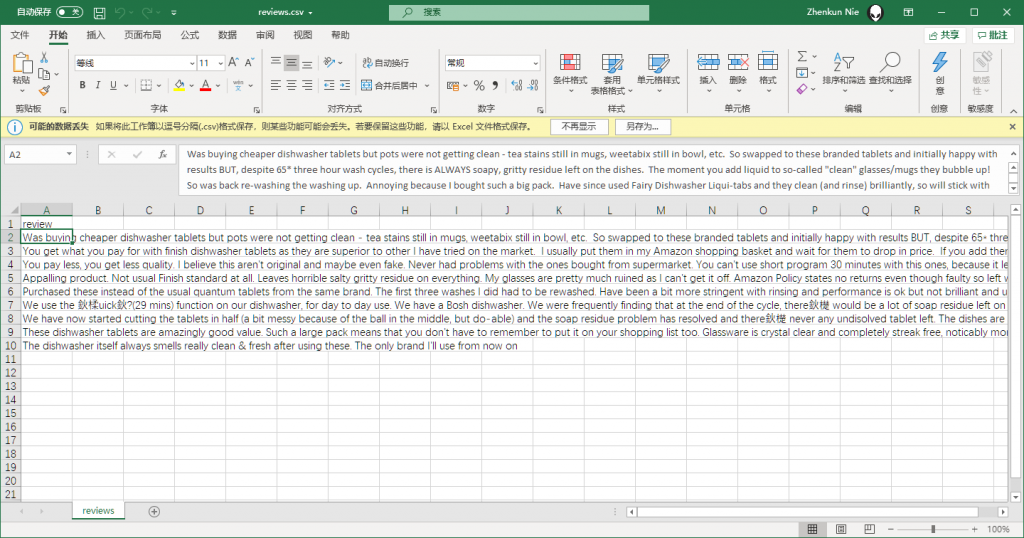
使用Scrapy自带方法导出效果如下:
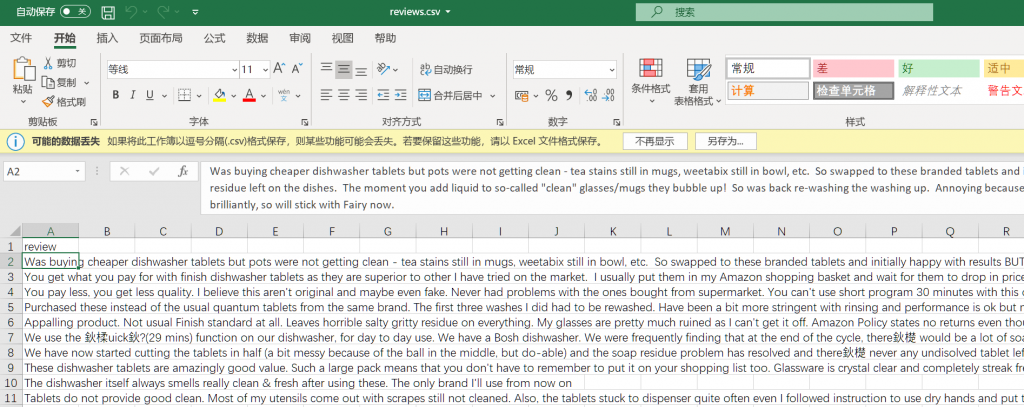
导出结果与scray自带导出方法的效果一致!

文章评论
666,此文章写的非常棒!简单易懂。