

模型训练
在项目文件根目录,创建一个data.yaml
#train 写存放训练集图片的文件地址#val 写存放测试集图片的文件地址
train: C:/Users/justi/AnacondaProjects/RKNNProjects/mis/mis/train/images
val: C:/Users/justi/AnacondaProjects/RKNNProjects/mis/mis/valid/images
#nc 标注的种类数量,name 里面放的输种类的名称
nc: 4
names: ['label1', 'label2', 'label3', 'label4']本案例使用yolov5s权重文件,修改models目录下的yolov5s.yaml,将nc后的数字修改成你的数据集中标注的种类数量
# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
# Parameters
nc: 4 # number of classes
depth_multiple: 0.33 # model depth multiple
width_multiple: 0.50 # layer channel multiple
........开始训练,打开终端,进入项目文件的目录,激活conda环境。输入
python train.py --data data.yaml --cfg models/yolov5s.yaml --data data.yaml --weights pretrained/yolov5s.pt --epoch 300 --batch-size 16 --device 0
#分割模型(segment目录下)
python train.py --data dataSeg.yaml --cfg ..\models\segment\yolov5s-seg.yaml --weights ..\pretrained\yolov5s.pt --epoch 300 --batch-size 32 --device 0- data.yaml指的是数据集的配置文件
- mask_yolov5s.yaml 指的是模型的配置文件
- pretrained/yolov5s.pt 使用yolov5spt的权重文件
- size 后面的数字指是多少张图片一起训练
- epoch 后面的数字表示跑的次数
- –device cpu或者数字代表显卡变化
训练结果保存在项目文件的run\train\exp文件中
如果报错:ModuleNotFoundError: No module named ‘matplotlib.pyplot’,则建议降级matplotlib版本,尝试:
conda install matplotlib==3.4.3模拟检测
在电脑端使用验证集验证模型检测结果
python detect.py --weights best.pt --data data.yaml --source data/mis/ RKNN优化
若使用默认的SiLU激活函数,则RK3588会使用CPU处理对应部分的任务。因此为了提升效率,需要手动修改激活函数为ReLU或其他。common.py构建模块。重构Conv模块,将SILU改为ReLU。
class Conv(nn.Module):
# Standard convolution with args(ch_in, ch_out, kernel, stride, padding, groups, dilation, activation)
#default_act = nn.SiLU() # default activation
default_act = nn.ReLU() # 修改激活函数
def __init__(self, c1, c2, k=1, s=1, p=None, g=1, d=1, act=True):
super().__init__()
self.conv = nn.Conv2d(c1, c2, k, s, autopad(k, p, d), groups=g, dilation=d, bias=False)
self.bn = nn.BatchNorm2d(c2)
self.act = self.default_act if act is True else act if isinstance(act, nn.Module) else nn.Identity()
def forward(self, x):
return self.act(self.bn(self.conv(x)))
def forward_fuse(self, x):
return self.act(self.conv(x))模型转换
PT模型转ONNX
瑞芯微针对特定版本的Yolov5s分支进行了修改。使用特定分支的Yolov5s时,在导出模型的时候不需要对yolovs/models/yolo.py进行修改。直接使用如下命令
python export.py --rknpu --weight yolov5s.pt若使用其他版本,则需对class Detect(nn.Module)进行如下修改:
def forward(self, x):
z = [] # inference output
for i in range(self.nl):
if os.getenv('RKNN_model_hack', '0') != '0':
z.append(torch.sigmoid(self.m[i](x[i])))
continue
x[i] = self.m[i](x[i]) # conv
bs, _, ny, nx = x[i].shape # x(bs,255,20,20) to x(bs,3,20,20,85)
x[i] = x[i].view(bs, self.na, self.no, ny, nx).permute(0, 1, 3, 4, 2).contiguous()
if not self.training: # inference
if self.onnx_dynamic or self.grid[i].shape[2:4] != x[i].shape[2:4]:
self.grid[i], self.anchor_grid[i] = self._make_grid(nx, ny, i)
y = x[i].sigmoid()
if self.inplace:
y[..., 0:2] = (y[..., 0:2] * 2 + self.grid[i]) * self.stride[i] # xy
y[..., 2:4] = (y[..., 2:4] * 2) ** 2 * self.anchor_grid[i] # wh
else: # for YOLOv5 on AWS Inferentia https://github.com/ultralytics/yolov5/pull/2953
xy, wh, conf = y.split((2, 2, self.nc + 1), 4) # y.tensor_split((2, 4, 5), 4) # torch 1.8.0
xy = (xy * 2 + self.grid[i]) * self.stride[i] # xy
wh = (wh * 2) ** 2 * self.anchor_grid[i] # wh
y = torch.cat((xy, wh, conf), 4)
z.append(y.view(bs, -1, self.no))
if os.getenv('RKNN_model_hack', '0') != '0':
return z
return x if self.training else (torch.cat(z, 1),) if self.export else (torch.cat(z, 1), x)修改为:
def forward(self, x):
z = [] # inference output
for i in range(self.nl):
x[i] = self.m[i](x[i]) # conv
return x此操作主要是为了将模型的输出对齐RKNN接收的格式——三个特征输出。
导出的模型,可以使用Netron对模型的架构进行查看。
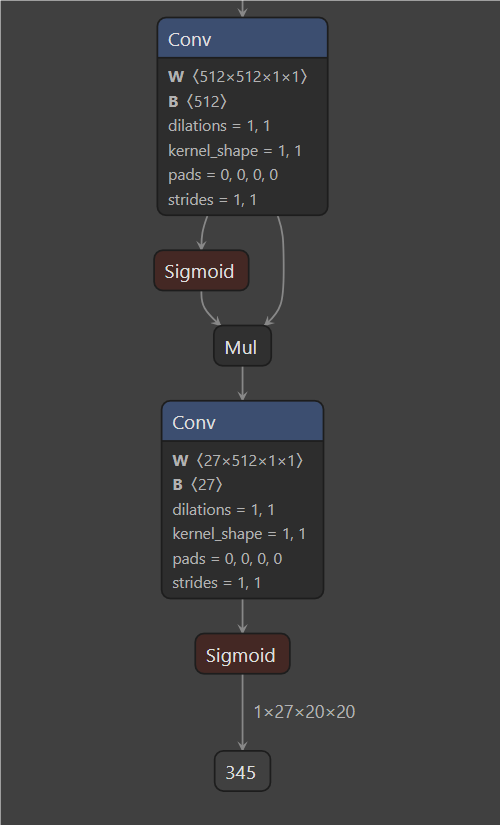
ONNX转RKNN
- platform选择对应的芯片平台
- MODEL_PATH选择对应的ONNX模型路径
- do_quantization=False/True决定是否对模型进行量化(不量化为fp16,量化完为int8)
- DATASET指定量化文件目录的路径,应为txt文件,内包括所有量化样本路径(样本在50左右)
import cv2
import numpy as np
from rknn.api import RKNN
import os
platform = 'rk3588'
MODEL_PATH = "best.onnx"
if __name__ == '__main__':
NEED_BUILD_MODEL = True
# NEED_BUILD_MODEL = False
# Create RKNN object
rknn = RKNN()
RKNN_MODEL_PATH = '{}_{}.rknn'.format(
MODEL_PATH, platform)
if NEED_BUILD_MODEL:
DATASET = './dataset.txt'
rknn.config(mean_values=[[0, 0, 0]], std_values=[
[255, 255, 255]], target_platform=platform)
# Load model
print('--> Loading model')
ret = rknn.load_onnx(MODEL_PATH)
if ret != 0:
print('load model failed!')
exit(ret)
print('done')
# Build model
print('--> Building model')
ret = rknn.build(do_quantization=False, dataset=DATASET)
if ret != 0:
print('build model failed.')
exit(ret)
print('done')
# Export rknn model
print('--> Export RKNN model: {}'.format(RKNN_MODEL_PATH))
ret = rknn.export_rknn(RKNN_MODEL_PATH)
if ret != 0:
print('Export rknn model failed.')
exit(ret)
print('done')
else:
ret = rknn.load_rknn(RKNN_MODEL_PATH)
rknn.release()转RKNN模型前,需要替换anchors_yolov5.txt文件内的参数,使用RKNN指定版本yolov5训练模型后,工程根目录会有一个RK_anchors.txt文件,将内参数复制过去即可。
连板调试
python yolov5.py --model ../model/yourmodel.rknn --img_show --target rk3588 --img_folder ../yourfolder精度分析
精度分析流程
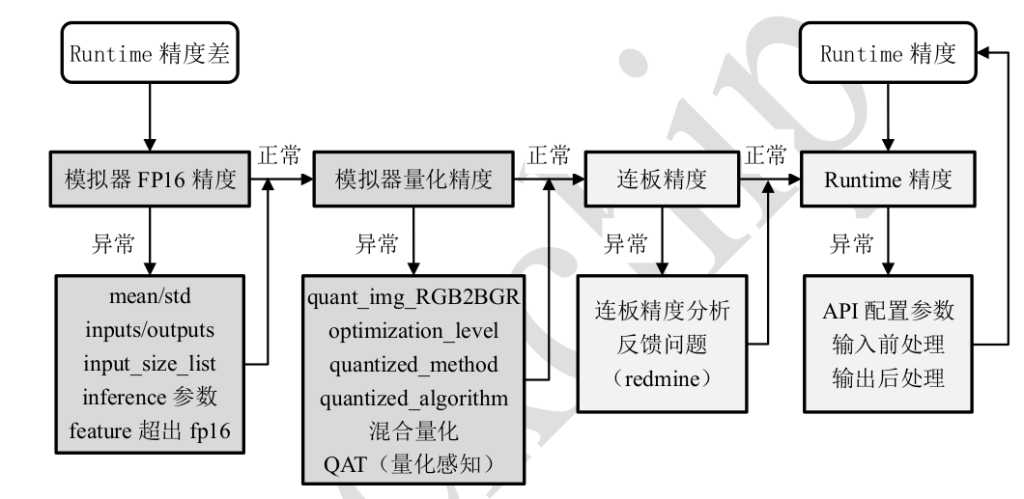
模拟器FP16精度
模拟器推理结果正确是板端 Runtime 推理正确的前提,所以需优先保证模拟器推理结果正确。 RKNN-Toolkit2 上的模拟器推理根据模型是否量化分为 FP16 推理和量化推理。FP16 推理结果正确是量化推理的结果正确的前提,因此当存在量化推理精度问题时,优先验证FP16 推理的正确性,再排查量化推理的精度问题。
模拟器在不开启量化的情况下,默认是FP16 的运算类型,所以只需要在使用 rknn.build()接口时,将do_quantization 参数设置为False , 即 可 以 将 原 始 模 型 转 换 为 FP16 的 RKNN 模 型 , 接 着 调 用rknn.init_runtime(target=None)和 rknn.inference()接口进行 FP16 模拟推理并获取输出结果。
import cv2
import numpy as np
from rknn.api import RKNN
import os
platform = 'rk3588'
MODEL_PATH = "best.onnx"
if __name__ == '__main__':
NEED_BUILD_MODEL = True
# NEED_BUILD_MODEL = False
# Create RKNN object
rknn = RKNN()
RKNN_MODEL_PATH = '{}_{}.rknn'.format(
MODEL_PATH, platform)
if NEED_BUILD_MODEL:
DATASET = './dataset.txt'
rknn.config(mean_values=[[0, 0, 0]], std_values=[
[255, 255, 255]], target_platform=platform)
# Load model
print('--> Loading model')
ret = rknn.load_onnx(MODEL_PATH)
if ret != 0:
print('load model failed!')
exit(ret)
print('done')
# Build model
print('--> Building model')
ret = rknn.build(do_quantization=False, dataset=DATASET)
if ret != 0:
print('build model failed.')
exit(ret)
print('done')
#accuracy_analysis
ret = rknn.accuracy_analysis(inputs=['a.jpg'], output_dir='snapshot', target='rk3588')
if ret != 0:
print('Analysis failed.')
exit(ret)
print('done')
#inference simulation
#rknn.init_runtime()
#outputs = rknn.inference(inputs=['bus.jpg'], data_format="nhwc")
rknn.release()若FP16模拟器输出结果错误,则需要进行以下检查:
- rknn 的 config 这个接口里:mean_values / std_values、input_size_list、inputs / outputs
- rknn 的 inference 这个接口里: inputs 和 data_format。python 环境下,图像数据都是通过cv2.imread读取的,图像格式为 BGR,大部分的 caffe 模型不用改;其他的一般输入为 RGB,需要cv2.cvtColor(img, cv2.COLOR_BGR2RGB)将图像数据转为 RGB, 才可以传给rknn的inference接口进行推理。
- 通过 cv2.imread 读取的图像数据的 layout 为 NHWC, 因为 data_format 的默认值为 NHWC, 因此不需要设置 data_format 参数;而如果模型的输入数据不是通过 cv2.imread 读取,此时用户就必须清楚知道输入数据的 layout 并设置正确的 data_format 参数,如果是图像数据,也要保证其 RGB 顺序与模型的输入 RGB 顺序一致
在经过“ fp16 模型” 的精度验证后, 排除了“ FP16 模型” 的错误可能, 就可以对模型进行量化, 并进一步对“ 量化模型” 进行精度分析。 如果在“量化模型” 遇到精度问题,将主要从以下几个方面进行排查:
- quantized_dtype量化类型的选择,Toolkit2-1.3.0,默认值为 asymmetric_quantized-8,asymmetric_quantized-16目前版本暂不支持。16-bit 量化和非量化(float16) 的运算性能差异不大,因此建议选择 fp16(rknn 的 build 接 口 的 do_quantization 设 为 False )的运算方式来代替16-bit量化;
- quant_img_RGB2BGR,一般用于caffe 模型;
- dataset,rknn 的 build 接口的量化校正集配置。 如果选择了和实际部署场景不大一致的校正集,则可能会出现精度下降的问题, 或者校正集的数量过多或过少都会影响精度( 一般选择 50~200张)
- quantized_algorithm
- quantized_method
- optimization_level
精度分析工具
rknn.build(do_quatization=True, dataset='./dataset.txt')
rknn.accuracy_analysis(inputs=[a.jpg], output_dir='snapshot', target='rk3588')该接口的功能是进行浮点,量化推理并产生每层的数据,用于量化精度分析。打印内容( 一般认为余弦相似度低于 0.99 存在少许不一致, 低于 0.98 几乎可以认为该层结果就是错误的)
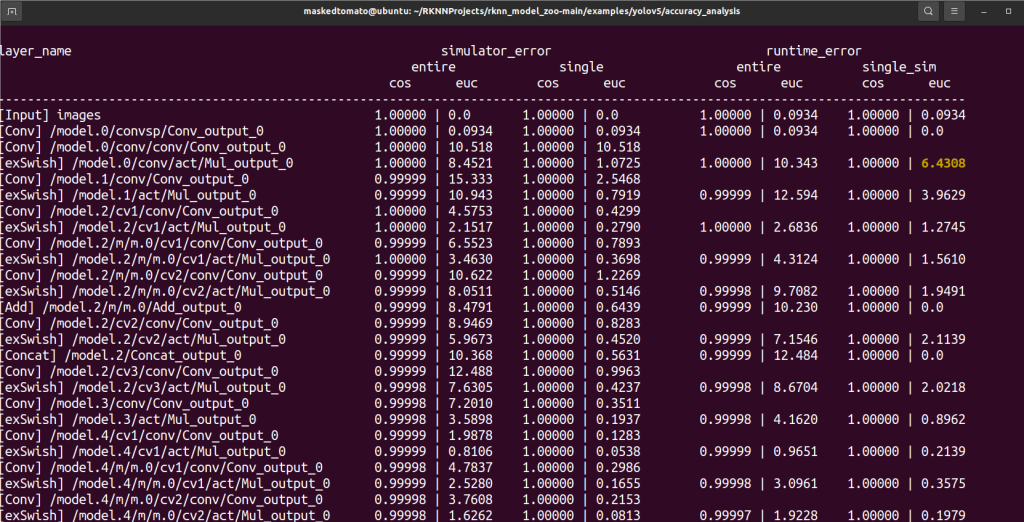
- simulator代表模拟器,runtime代表板端。
- enter代表网络整体相似度,single代表单层相似度。
- cos代表余弦距离,euc代表欧氏距离。
文章评论